Imagina que tienes un montón de documentos internos de tu empresa: manuales, FAQs, políticas, fichas de producto, informes. Quieres que un chatbot pueda responder preguntas basándose en esa información. No en lo que "sabe" GPT de internet, sino en TUS documentos.
Eso es exactamente lo que hace RAG (Retrieval Augmented Generation). Y en este tutorial vas a construir uno funcional desde cero.
No es tan complicado como suena. Te lo prometo.
Qué es RAG y Por Qué lo Necesitas
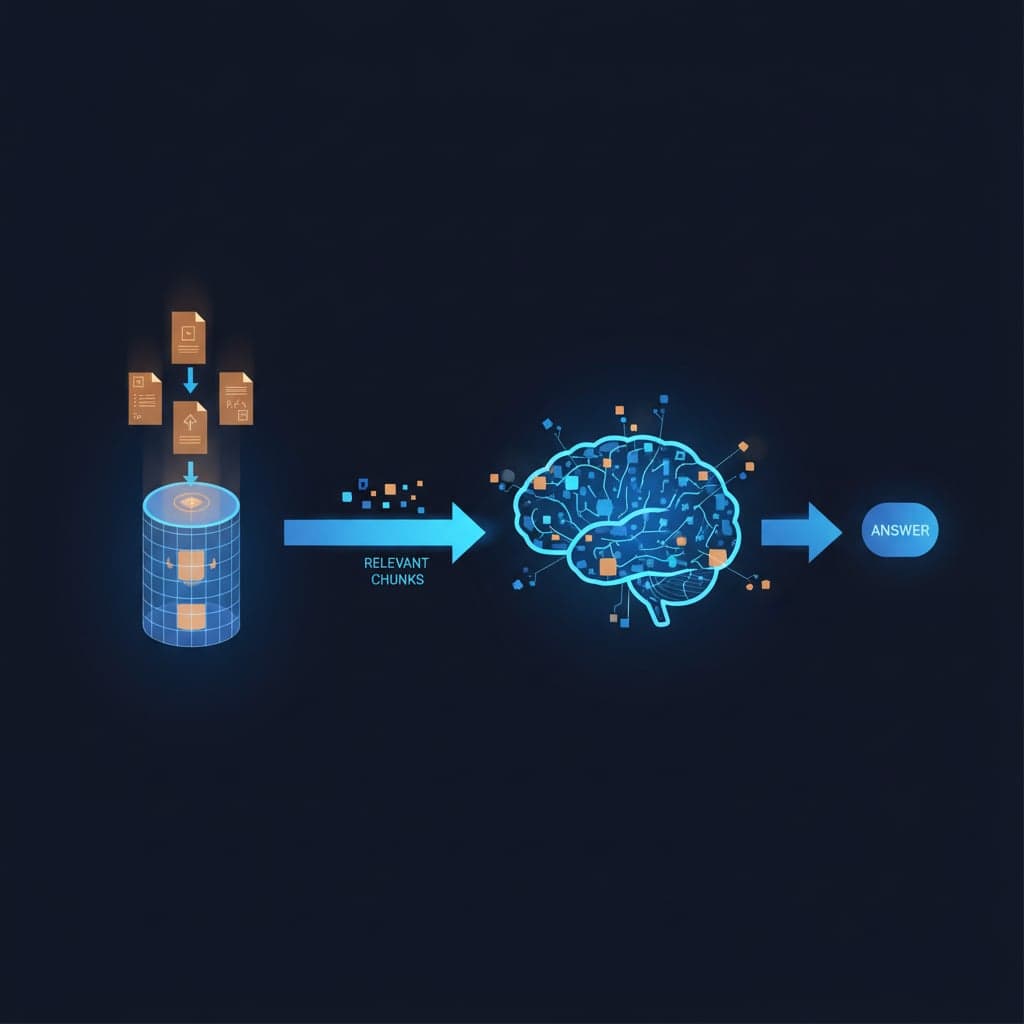
RAG son las siglas de Retrieval Augmented Generation, que traducido sería algo como "generación aumentada por recuperación". El nombre es horrible, pero el concepto es simple:
- El usuario hace una pregunta
- El sistema busca en tus documentos los fragmentos más relevantes
- Esos fragmentos se envían al LLM como contexto
- El LLM genera una respuesta basada en esos fragmentos específicos
¿Por qué no simplemente meter todos los documentos en el prompt?
Porque los LLMs tienen un límite de contexto (aunque sea grande). Si tienes 500 documentos de 20 páginas cada uno, no caben. Y aunque cupieran, el modelo se pierde con tanto contexto y las respuestas empeoran.
RAG resuelve esto: solo le das al modelo los 3-5 fragmentos más relevantes para cada pregunta. Es como darle a alguien las páginas exactas de una enciclopedia en vez de toda la enciclopedia.
El flujo completo de RAG
Fase 1: Indexación (se hace una vez)
- Divides tus documentos en fragmentos pequeños (chunks)
- Conviertes cada fragmento en un vector numérico (embedding)
- Almacenas los vectores en una base de datos vectorial
Fase 2: Consulta (cada vez que alguien pregunta)
- Conviertes la pregunta del usuario en un vector
- Buscas los vectores más similares en la base de datos
- Recuperas los fragmentos de texto correspondientes
- Envías la pregunta + fragmentos al LLM
- El LLM genera una respuesta basada en esos fragmentos

Paso 1: Preparar tus Documentos
Antes de escribir código, necesitas preparar tus documentos. RAG funciona con prácticamente cualquier formato de texto:
- Word (.docx)
- Texto plano (.txt, .md)
- CSV / Excel
- Páginas web
- Correos electrónicos
Organiza tus documentos
- Crea una carpeta llamada
documentos/en tu proyecto - Mete todos los archivos que quieras que tu chatbot pueda consultar
- Limpia si hace falta: elimina cabeceras/pies de página repetitivos, índices que no aportan, etc.
Para este tutorial, vamos a usar archivos PDF y texto. Si quieres seguir el ejemplo exacto, crea 2-3 archivos .txt con información sobre un tema (por ejemplo, la política de devoluciones de una tienda ficticia, un manual de producto, unas FAQs).
Paso 2: Configurar el Entorno
# Crear el proyecto
mkdir mi-rag
cd mi-rag
# Entorno virtual
python -m venv venv
source venv/bin/activate # Windows: venv\Scripts\activate
# Instalar dependencias
pip install langchain langchain-openai langchain-community
pip install chromadb # Base de datos vectorial local
pip install pypdf # Para leer PDFs
pip install python-dotenv
Crea tu archivo .env:
OPENAI_API_KEY=tu-api-key-aqui
¿Por qué estas herramientas?
| Herramienta | Para qué | Alternativas |
|---|---|---|
| LangChain | Orquestar todo el flujo RAG | LlamaIndex, Haystack |
| ChromaDB | Base de datos vectorial (local) | Pinecone (cloud), Supabase, Weaviate |
| OpenAI Embeddings | Convertir texto en vectores | Cohere, modelos locales |
| GPT-4o-mini | Generar respuestas | Claude, Llama, Mistral |
Usamos ChromaDB porque es local (no necesitas crear cuenta en ningún lado) y perfecto para empezar. Para producción, probablemente querrás Pinecone o Supabase.
Nota Importante
Presta atención a este detalle.
Paso 3: Cargar y Dividir Documentos
Crea un archivo indexar.py:
from dotenv import load_dotenv
from langchain_community.document_loaders import (
DirectoryLoader,
TextLoader,
PyPDFLoader
)
from langchain.text_splitter import RecursiveCharacterTextSplitter
load_dotenv()
# 1. CARGAR DOCUMENTOS
# Cargar todos los .txt de la carpeta documentos/
txt_loader = DirectoryLoader(
"documentos/",
glob="**/*.txt",
loader_cls=TextLoader,
loader_kwargs={"encoding": "utf-8"}
)
# Cargar todos los .pdf
pdf_loader = DirectoryLoader(
"documentos/",
glob="**/*.pdf",
loader_cls=PyPDFLoader
)
# Combinar todos los documentos
documents = txt_loader.load() + pdf_loader.load()
print(f"Documentos cargados: {len(documents)}")
# 2. DIVIDIR EN CHUNKS
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # Tamaño de cada fragmento (caracteres)
chunk_overlap=200, # Solapamiento entre fragmentos
length_function=len,
separators=["\n\n", "\n", ". ", " ", ""]
)
chunks = text_splitter.split_documents(documents)
print(f"Chunks creados: {len(chunks)}")
# Ver un ejemplo
print(f"\nEjemplo de chunk:")
print(f"Contenido: {chunks[0].page_content[:200]}...")
print(f"Metadata: {chunks[0].metadata}")
¿Por qué dividir en chunks?
Los documentos completos son demasiado grandes para enviar como contexto al LLM. Dividiéndolos en fragmentos de 1000 caracteres:
- Cada fragmento tiene una idea coherente
- El sistema puede recuperar solo los fragmentos relevantes
- El LLM recibe contexto preciso, no ruido
Pro tip: El chunk_size y chunk_overlap son los parámetros más importantes para la calidad de tu RAG. Si tus chunks son demasiado pequeños, pierden contexto. Si son demasiado grandes, incluyen información irrelevante. 1000 caracteres con 200 de overlap es un buen punto de partida.
Paso 4: Crear Embeddings y Almacenar en ChromaDB
Añade al archivo indexar.py (o crea crear_bd.py):
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
# 3. CREAR EMBEDDINGS Y ALMACENAR
embeddings = OpenAIEmbeddings(
model="text-embedding-3-small" # Modelo de embeddings rápido y barato
)
# Crear la base de datos vectorial con ChromaDB
vectorstore = Chroma.from_documents(
documents=chunks,
embedding=embeddings,
persist_directory="./chroma_db", # Se guarda en disco
collection_name="mi_base_conocimiento"
)
print(f"\nBase de datos vectorial creada con {len(chunks)} fragmentos")
print("Guardada en ./chroma_db/")
Ejecuta:
python indexar.py
Esto crea una carpeta chroma_db/ con todos tus documentos indexados. Solo necesitas ejecutar esto una vez (o cuando añadas nuevos documentos).
¿Cuánto cuesta crear los embeddings?
El modelo text-embedding-3-small cuesta 0.02$/1M tokens. Para poner en perspectiva:
- 100 páginas de texto = ~50,000 tokens = ~0.001$
- 1000 páginas = ~0.01$
Es prácticamente gratis.

Paso 5: Crear el Sistema de Consulta
Ahora la parte divertida. Crea consultar.py:
from dotenv import load_dotenv
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_community.vectorstores import Chroma
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
load_dotenv()
# 1. CARGAR LA BASE DE DATOS VECTORIAL
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
vectorstore = Chroma(
persist_directory="./chroma_db",
embedding_function=embeddings,
collection_name="mi_base_conocimiento"
)
# 2. CONFIGURAR EL RETRIEVER
retriever = vectorstore.as_retriever(
search_type="similarity",
search_kwargs={"k": 4} # Recuperar los 4 fragmentos más relevantes
)
# 3. DEFINIR EL PROMPT
prompt_template = """Usa los siguientes fragmentos de contexto para responder la pregunta del usuario.
Si no encuentras la respuesta en el contexto, di claramente que no tienes esa información.
No inventes respuestas. Basa tu respuesta SOLO en el contexto proporcionado.
Contexto:
{context}
Pregunta: {question}
Respuesta útil:"""
prompt = PromptTemplate(
template=prompt_template,
input_variables=["context", "question"]
)
# 4. CREAR LA CADENA RAG
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0.2)
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff", # Mete todo el contexto de golpe
retriever=retriever,
chain_type_kwargs={"prompt": prompt},
return_source_documents=True # Devuelve las fuentes
)
# 5. HACER CONSULTAS
def preguntar(pregunta):
resultado = qa_chain.invoke({"query": pregunta})
print(f"\nPregunta: {pregunta}")
print(f"\nRespuesta: {resultado['result']}")
print(f"\nFuentes utilizadas:")
for i, doc in enumerate(resultado['source_documents'], 1):
print(f" {i}. {doc.metadata.get('source', 'desconocido')} - \"{doc.page_content[:100]}...\"")
print("-" * 60)
return resultado
# Probar
preguntar("¿Cuál es la política de devoluciones?")
preguntar("¿Qué productos tenéis disponibles?")
preguntar("¿Cuál es el horario de atención al cliente?")
Ejecuta:
python consultar.py
Si todo va bien, verás respuestas basadas exclusivamente en tus documentos, con las fuentes citadas. Eso es RAG en acción.
Marketing digital para profesiones similares
Si te ha resultado útil esta guía, estas otras de marketing para profesiones del mismo sector también te pueden interesar:
- Marketing para dentistas
- Marketing para fisioterapeutas
- Marketing para nutricionistas
- Marketing para psicólogos
- Marketing para podólogos
- Marketing para ópticas
- Marketing para farmacias
- Marketing para veterinarios
Marketing digital para profesiones similares
Si te ha resultado útil esta guía, estas otras de marketing para profesiones del mismo sector también te pueden interesar:
- Marketing para clínicas
- Marketing para fisioterapeutas
- Marketing para nutricionistas
- Marketing para psicólogos
- Marketing para podólogos
- Marketing para ópticas
- Marketing para farmacias
- Marketing para veterinarios
Marketing digital para profesiones similares
Si te ha resultado útil esta guía, estas otras de marketing para profesiones del mismo sector también te pueden interesar:
- Marketing para clínicas
- Marketing para dentistas
- Marketing para nutricionistas
- Marketing para psicólogos
- Marketing para podólogos
- Marketing para ópticas
- Marketing para farmacias
- Marketing para veterinarios
Marketing digital para profesiones similares
Si te ha resultado útil esta guía, estas otras de marketing para profesiones del mismo sector también te pueden interesar:
- Marketing para clínicas
- Marketing para dentistas
- Marketing para fisioterapeutas
- Marketing para psicólogos
- Marketing para podólogos
- Marketing para ópticas
- Marketing para farmacias
- Marketing para veterinarios
Marketing digital para profesiones similares
Si te ha resultado útil esta guía, estas otras de marketing para profesiones del mismo sector también te pueden interesar:
- Marketing para clínicas
- Marketing para dentistas
- Marketing para fisioterapeutas
- Marketing para nutricionistas
- Marketing para podólogos
- Marketing para ópticas
- Marketing para farmacias
- Marketing para veterinarios
Marketing digital para profesiones similares
Si te ha resultado útil esta guía, estas otras de marketing para profesiones del mismo sector también te pueden interesar:
- Marketing para clínicas
- Marketing para dentistas
- Marketing para fisioterapeutas
- Marketing para nutricionistas
- Marketing para psicólogos
- Marketing para ópticas
- Marketing para farmacias
- Marketing para veterinarios
Marketing digital para profesiones similares
Si te ha resultado útil esta guía, estas otras de marketing para profesiones del mismo sector también te pueden interesar:
- Marketing para clínicas
- Marketing para dentistas
- Marketing para fisioterapeutas
- Marketing para nutricionistas
- Marketing para psicólogos
- Marketing para podólogos
- Marketing para farmacias
- Marketing para veterinarios
Marketing digital para profesiones similares
Si te ha resultado útil esta guía, estas otras de marketing para profesiones del mismo sector también te pueden interesar:
- Marketing para clínicas
- Marketing para dentistas
- Marketing para fisioterapeutas
- Marketing para nutricionistas
- Marketing para psicólogos
- Marketing para podólogos
- Marketing para ópticas
- Marketing para veterinarios
Marketing digital para profesiones similares
Si te ha resultado útil esta guía, estas otras de marketing para profesiones del mismo sector también te pueden interesar:
- Marketing para clínicas
- Marketing para dentistas
- Marketing para fisioterapeutas
- Marketing para nutricionistas
- Marketing para psicólogos
- Marketing para podólogos
- Marketing para ópticas
- Marketing para farmacias
Marketing digital para profesiones similares
Si te ha resultado útil esta guía, estas otras de marketing para profesiones del mismo sector también te pueden interesar:
- Marketing para cerrajeros
- Marketing para pintores
- Marketing para jardineros
- Marketing para empresas de limpieza
- Marketing para mudanzas
- Marketing para mecánicos
Marketing digital para profesiones similares
Si te ha resultado útil esta guía, estas otras de marketing para profesiones del mismo sector también te pueden interesar:
- Marketing para fontaneros
- Marketing para pintores
- Marketing para jardineros
- Marketing para empresas de limpieza
- Marketing para mudanzas
- Marketing para mecánicos
Marketing digital para profesiones similares
Si te ha resultado útil esta guía, estas otras de marketing para profesiones del mismo sector también te pueden interesar:
- Marketing para fontaneros
- Marketing para cerrajeros
- Marketing para jardineros
- Marketing para empresas de limpieza
- Marketing para mudanzas
- Marketing para mecánicos
Marketing digital para profesiones similares
Si te ha resultado útil esta guía, estas otras de marketing para profesiones del mismo sector también te pueden interesar:
- Marketing para fontaneros
- Marketing para cerrajeros
- Marketing para pintores
- Marketing para empresas de limpieza
- Marketing para mudanzas
- Marketing para mecánicos
Marketing digital para profesiones similares
Si te ha resultado útil esta guía, estas otras de marketing para profesiones del mismo sector también te pueden interesar:
- Marketing para fontaneros
- Marketing para cerrajeros
- Marketing para pintores
- Marketing para jardineros
- Marketing para mudanzas
- Marketing para mecánicos
Marketing digital para profesiones similares
Si te ha resultado útil esta guía, estas otras de marketing para profesiones del mismo sector también te pueden interesar:
- Marketing para fontaneros
- Marketing para cerrajeros
- Marketing para pintores
- Marketing para jardineros
- Marketing para empresas de limpieza
- Marketing para mecánicos
Marketing digital para profesiones similares
Si te ha resultado útil esta guía, estas otras de marketing para profesiones del mismo sector también te pueden interesar:
- Marketing para fontaneros
- Marketing para cerrajeros
- Marketing para pintores
- Marketing para jardineros
- Marketing para empresas de limpieza
- Marketing para mudanzas
Marketing digital para profesiones similares
Si te ha resultado útil esta guía, estas otras de marketing para profesiones del mismo sector también te pueden interesar:
Marketing digital para profesiones similares
Si te ha resultado útil esta guía, estas otras de marketing para profesiones del mismo sector también te pueden interesar:
Inteligencia Artificial aplicada a negocio
Sin humo. Solo experimentos reales, prompts que funcionan y estrategias de escalabilidad.
Paso 6: Convertirlo en un Chat Interactivo
Vamos a crear una versión interactiva que puedas usar como chatbot:
# chat_rag.py
from dotenv import load_dotenv
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_community.vectorstores import Chroma
from langchain.chains import ConversationalRetrievalChain
from langchain.memory import ConversationBufferWindowMemory
load_dotenv()
# Configurar componentes
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
vectorstore = Chroma(
persist_directory="./chroma_db",
embedding_function=embeddings,
collection_name="mi_base_conocimiento"
)
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0.2)
memory = ConversationBufferWindowMemory(
memory_key="chat_history",
return_messages=True,
k=5 # Recuerda las últimas 5 interacciones
)
# Cadena conversacional con RAG
qa_chain = ConversationalRetrievalChain.from_llm(
llm=llm,
retriever=vectorstore.as_retriever(search_kwargs={"k": 4}),
memory=memory,
return_source_documents=True
)
# Chat interactivo
print("Chat con tu base de conocimiento (escribe 'salir' para terminar)")
print("=" * 50)
while True:
pregunta = input("\nTú: ")
if pregunta.lower() == "salir":
break
resultado = qa_chain.invoke({"question": pregunta})
print(f"\nIA: {resultado['answer']}")
Este chat recuerda el contexto de la conversación. Puedes preguntar "¿Y qué más me puedes decir sobre eso?" y entenderá a qué te refieres.
Alternativas a ChromaDB para Producción
ChromaDB es perfecto para desarrollo y proyectos pequeños. Para producción, considera estas alternativas:
Pinecone (Cloud)
from langchain_pinecone import PineconeVectorStore
import os
os.environ["PINECONE_API_KEY"] = "tu-api-key"
vectorstore = PineconeVectorStore.from_documents(
documents=chunks,
embedding=embeddings,
index_name="mi-indice"
)
Pros: Escalable, rápido, serverless. Contras: Coste por uso, tus datos en la nube.
Supabase (PostgreSQL + pgvector)
from langchain_community.vectorstores import SupabaseVectorStore
from supabase import create_client
supabase = create_client("tu-url", "tu-key")
vectorstore = SupabaseVectorStore.from_documents(
documents=chunks,
embedding=embeddings,
client=supabase,
table_name="documents"
)
Pros: PostgreSQL que ya conoces, open source, buen plan gratuito. Contras: Necesitas configurar la extensión pgvector.
| Base Vectorial | Tipo | Precio | Mejor para |
|---|---|---|---|
| ChromaDB | Local | Gratis | Desarrollo, prototipos |
| Pinecone | Cloud | Desde 0$ (free tier) | Producción serverless |
| Supabase | Cloud/Self-host | Desde 0$ (free tier) | Si ya usas Supabase |
| Weaviate | Cloud/Self-host | Desde 0$ | Búsqueda avanzada |
| Qdrant | Cloud/Self-host | Desde 0$ | Alto rendimiento |
Paso 7: Optimizar la Calidad de las Respuestas
Tu RAG básico funciona, pero hay formas de mejorar significativamente la calidad:
1. Ajustar el tamaño de chunks
Experimenta con diferentes tamaños:
# Para documentos técnicos densos
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=100
)
# Para documentos narrativos
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1500,
chunk_overlap=300
)
2. Añadir metadata a los chunks
# Enriquecer los chunks con metadata
for chunk in chunks:
chunk.metadata["tipo"] = "faq" # o "manual", "politica", etc.
chunk.metadata["fecha"] = "2026-01"
Esto te permite filtrar por tipo de documento en las búsquedas.
3. Usar Hybrid Search
Combina búsqueda semántica (por significado) con búsqueda por keywords:
from langchain.retrievers import EnsembleRetriever
from langchain_community.retrievers import BM25Retriever
# Retriever semántico (embeddings)
semantic_retriever = vectorstore.as_retriever(search_kwargs={"k": 3})
# Retriever por keywords (BM25)
bm25_retriever = BM25Retriever.from_documents(chunks, k=3)
# Combinar ambos
hybrid_retriever = EnsembleRetriever(
retrievers=[semantic_retriever, bm25_retriever],
weights=[0.6, 0.4] # 60% semántico, 40% keywords
)
Pro tip: Hybrid search mejora mucho los resultados cuando las preguntas incluyen términos técnicos o nombres propios que la búsqueda semántica sola puede no captar.


¿Te preocupa el futuro con la IA?
Descubre cómo la inteligencia artificial ha liquidado las viejas reglas del juego y qué puedes hacer tú al respecto.
Leer más sobre el libroErrores Comunes en RAG
Chunks demasiado grandes o pequeños. Si tus chunks son de 5000 caracteres, incluyen demasiada información irrelevante. Si son de 100 caracteres, pierden contexto. Empieza con 1000 y ajusta.
No solapar chunks. Sin overlap, un concepto que está entre dos chunks se pierde. Siempre usa overlap (20% del chunk_size es un buen valor).
No limpiar los documentos. Headers, footers, números de página, índices... todo eso añade ruido. Limpia tus documentos antes de indexarlos.
Recuperar demasiados o pocos fragmentos. Con k=1 puedes perderte información relevante. Con k=20 inundas al LLM de contexto y la calidad baja. k=3 a 5 suele ser el sweet spot.
No evaluar la calidad. Crea un set de 20-30 preguntas con respuestas esperadas y evalúa regularmente tu RAG. Sin métricas, no sabes si los cambios mejoran o empeoran las cosas.
Olvidar actualizar el índice. Si tus documentos cambian, necesitas re-indexar. Implementa un proceso para detectar cambios y actualizar los embeddings.
Conclusión: Tu Base de Conocimiento con IA
Acabas de construir algo que hace unos años habría costado meses de desarrollo y miles de euros: un sistema que entiende tus documentos y responde preguntas basándose en ellos.
Resumen de lo que has aprendido:
- Cargar y dividir documentos en chunks optimizados
- Crear embeddings y almacenarlos en una base vectorial
- Consultar con búsqueda semántica + LLM
- Optimizar con hybrid search, metadata y ajuste de parámetros
El siguiente paso natural es desplegar esto como una API o integrarlo en tu web. Un endpoint Flask/FastAPI que reciba preguntas y devuelva respuestas es todo lo que necesitas para convertir este script en un producto funcional.
Empieza con tus documentos más importantes (FAQs, manuales de producto) y ve ampliando. Un RAG bien hecho puede reducir drásticamente el volumen de soporte al cliente y dar acceso instantáneo a información que antes requería buscar manualmente durante minutos.